Part 3 데이터를 기반한 제품 개선
3. 데이터 기반 제품 개선
3-1. 데이터 기반 제품 개선이란?
머신러닝을 기반으로 한 제품 개선이 무엇인지 알아보자
데이터 기반 제품 개선이란?
데이터를 가지고 머신러닝을 통해 패턴을 분석하고 미래를 예측하는 것
제품 사용자들의 행동 등을 보고 개인화 형태로 추천해주는 것
모든 사람에 해당되는게 아니라 개인의 관점에 따라 제품을 추천해주는 것
운영 상의 비용을 머신러닝을 통해 최소화 하는 것
공장 운영 시 공정 상의 다양한 이슈들을 미리 예측하는 것으로 비용을 최소화
Cutomer Support 경우 챗봇 등을 이용해 비용 절감 가능
데이터 과학자의 역할
- 머신러닝의 형태로 사용자들의 경험을 개선
문제에 맞춰 가설을 세우고 데이터를 수집한 후에 예측 모델을 만들고 이를 테스트
- 장시간이 필요하지만 이를 짧은 사이클로 단순하게 시작해서(애자일 방법론) 고도화하는 것이 좋음
테스트는 가능하면 A/B 테스트(실제 사용자들에게 노출시켜 테스트 하는 것)를 수행하는 것이 더 좋음
데이터 과학자에게 필요한 스킬셋
머신러닝/인공지능에 대한 깊은 지식과 경험
Python, SQL 능력
통계 지식, 수학 지식
끈기와 열정
훌륭한 데이터 과학자란?
- 열정, 끈기가 있는 사람
- 다양한 경험이 있는 사람
- 코딩 능력이 있는 사람
- 현실적인 접근 방법을 생각하는 사람
- 애자일 기반의 모델링
- 딥러닝이 모든 문제의 해답은 아님을 명심
- 과학적인 접근 방법을 생각하는 사람(지표기반 접근, 목표가 무엇이고 어떻게 측정할 것인지)
- 모델링을 위한 데이터의 존재 여부
모델 개발 전체 과정(Life-Cycle)
문제 정의 -> 훈련용 데이터 수집 -> 모델 빌딩과 테스트 -> 모델 A/B 테스트 -> 전체 론치(결과 괜찮을 시), A/B 결과 분석-> 훈련용 데이터 수집(결과 나쁠 시)
3-2. 데이터 기반 제품 개선 케이
머신러닝 모델링 예 - 개인화된 추천 엔진
- 유데미 : 규칙 기반에서 머신러닝 기반으로 전환
머신러닝 전에는 마케터들이 규칙 기반으로 추천 : A/B 테스트가 중요해짐
머신러닝 모델링 예 - 사기 결제 감지
훈련 데이터를 수집하는 두 가지 방법 : 실제 사례 수집(신용카드 회사와 협업, 이상값 탐지를 실행하고 사람에게 검토 요청(휴먼 인더 루프)
가격이 비싼 신규 코스가 며칠 만에 정가로 판매됨 -> 의심스러움
>> 강의 대충 찍고 비싸게 올린 다음 훔친 카드로 결제 후 강의 닫음
다른 지표 : 머신러닝의 편향성(bias로 인해 중국에서 결제가 일어났는데 이 데이터로 인해 중국에서 유데미 강의를 결제하면 무조건 사기 결제로 감지하는 경우, 신약 개발 시 백인 남성 데이터만 수집하는 경우 다양한 인종에 대해서는 편향이 생김) 또는 머신러닝 윤리의 중요성
머신러닝 모델링 예 - 환자 이상 징후 예측
원격 환자 모니터링(Remote Patient Monitoring)에서 많이 사용됨
환자의 다양한 측정 데이터를 기반으로 환자의 상태가 혹시라도 치료를 필요로 하는지 예측
목표는 환자의 병원 입원이나 응급실 방문을 막는 것임
머신러닝 모델링 예 - 농업용 자율 트랙터
존디어는 ML을 사용해 자율 트랙터 개발
>> 밭을 탐색하고 사람보다 더 효율적으로 심기 및 수확과 같은 작업을 수행
의료 이미지(Medical Imaging) 분석
- 전에는 x-ray 이미지를 사람이 했는데, 지금은 AI가 하고 있음. 더 빠르고 정확함
- VoxelMorph라는 오픈소스 프레임워크는 딥러닝으로 몇 초만에 MRI 분석
잘못 진단된 경우 누구의 책임인지에 대한 의견이 있었음
- 초음파 사진 기반의 심장병 진단 기술
Caption Health는 초음파 사진 기반의 심장병 진단 기술 개발
> 인공지능 기반의 이미징 기술로 FDA 승인 받음
> 기존 엑스레이 기반의 CT Scan과 비교하면 안정성과 비용과 시간 부문에서 엄청난 이점 존재
3-3. 머신러닝이란?
머신러닝이란?
구체적으로 프로그래밍을 하지 않고 배울 수 있는 능력을 컴퓨터에게 주는 분야의 연구
코딩을 하지 않고 모델에게 데이터를 주면 모델이 개/고양이에 대한 패턴을 추출해서 분류하는 능력을 줄 수 있는 것
- 배움이 가능한 기계의 개발
- 학습의 종류에 따라 방법이 달라짐
- 결국 데이터의 패턴을 보고 흉내내는 방식(imitation)
- 컴퓨터가 학습할 수 있도록 하는 알고리즘과 기술을 개발하는 분야
- 딥러닝은 이 중의 일부
- 비전, 자연어처리 등에 적용됨
- AI는 머신러닝을 포괄하는 개념
머신러닝 모델이란?
머신러닝을 통해 최종적으로 만드는 것이 머신러닝 모델
- 머신러닝을 통해 만들어진 특정 방식의 예측을 해주는 블랙박스
- 선택한 머신러닝 알고리즘에 따라 내부가 달라짐
- 디버깅은 쉽지 않음
입력 데이터를 주면 그를 기반으로 예측 : Supervised Learning(지도학습)
MLOps
실제 서비스에서 사용하기 위해 모델을 배포하고 API 형태로 사용할 수 있게 만드는 것
모델 트레이닝/빌딩
머신러닝 모델을 만드는 것
머신러닝 종류
- 지도 기계 학습(Supervised Machine Learning)
Classification(Binary, Multi-class)/Regression이 있음
- 비지도 기계 학습(Unsupervised Machine Learning)
클러스터링 혹은 그룹핑처럼 주어진 데이터를 몇 개의 그룹으로 분리
반지도학습(Semi-supervised learning)도 비지도학습에 포함됨
- 강화 학습(Reinforcement Learning)
알파고 혹은 자율주행
지도 기계 학습 예제 : 타이타닉 승객 생존 여부 예측
이진 분류 문제(Binary Classification)
탑승 승객별로 승객 정보와 최종 생존 여부가 학습 데이터로 제공됨
최종 생존 여부처럼 모델이 예측해야 하는 필드를 레이블/타켓이라고 부름
Feature Engineering : 기존 필드로부터 새로운 필드를 뽑아내는 것이 일반적
지도 기계 학습
학습 데이터 X, Y를 학습에 사용
X : 입력 데이터(feature)
Y : 예측값(label)
X, Y를 학습 알고리즘이 있는 머신러닝 모델에 학습 시킴
추론/예측 : X를 머신러닝 모델에 통과시켜 예측값을 도출하고 Y를 기준으로 어떻게 정답 여부를 확인
지도 학습 예 : 스팸 웹 페이지 분류기
정상적인 문서 : 클라우드 컴퓨팅이란 집적, 공유된 정보통신 기기...
비정상적 문서 : 클라우드 컴퓨팅, 온라인 도박, 간편 즉시 대출
비정상적 문서에서는 키워드로만 문서가 구성되어 있는데 해당 키워드가 검색될 때 광고를 하는 스팸임
비정상적 문서는 명사만 있음
정상적 문서에는 조사 등의 다양한 품사가 있는데 각 비율을 따져서 스팸 여부를 확인
비지도 학습 예 : Language Model
문장의 일부를 보고 비어있는 단어를 확률적으로 맞추는 모델
훈련은 위키피디아에 있는 자연스러운 문장들을 대상으로 진행
블랙박스임
문장을 하나 주고 Context Window 형태로 좌측 > 우측 형태로 이동시키며 다음에 나올 단어를 정답으로 주고 예측하게 학습 시킴
OpenAI/transitoned/from/non-propit/to/for-profit
["OpenAI transitoned from", "non-propit"]
["transitoned from non-progit", "to"]
["from non-profit to", "for-propit"]
이 경우 context window = 4
3개의 토큰을 보고 1개의 토큰 예측을 훈련
Context window가 클수록 모델의 힘이 커지고, 크기가 모델의 메모리를 결정
OpenAI transitoned from이 인풋이면 출력이 non-profit이 되도록 학습 돼야함
다음으로 이동시키면 transitoned from non-progit가 입력, to가 출력
3-4. ML 모델 개발 시 고려할 점
모델 개발 시 데이터 과학자들의 일반적인 생각
데이터 과학자 : 아주 좋은 머신러닝 모델을 만들겠다.
엔지니어(DevOps, Backend) : 모델 만들고 다음 스텝은 뭐니?
데이터 과학자 : ??
모델 개발 시 엔지니어들의 일반적인 생각
엔지니어 : 머신러닝 모델을 받긴 했는데 어떻게 배포하지?
시간이 지난 후
데이터 과학자 : 모델 론치 잘 됐어?
엔지니어 : 응
마찰이 생기는 지점 - 개발된 모델의 이양 관련
많은 수의 데이터 과학자들은 R을 비롯한 다양한 툴로 모델을 개발
하지만 실제 프로덕션 환경은 다양한 모델들을 지원하지 못함
> 다른 언어로 포팅하는 상황이 발생하고 개발/검증된 모델의 프로덕션 환경 론치 시 시간이 오래 걸리고 오류 가능성이 존재함
> 심한 경우 모델 관련 개발을 다시 해야함(피쳐 계산과 모델 실행 관련)
모델 개발 시 꼭 기억해야 할 포인트 1
모델 개발부터 론치까지 책임질 사람이 필요하다.
- 모델 개발은 시작일뿐 성공적인 프로덕션 론치가 최종적 목표임
- 이 일에 참여하는 사람들이 같이 크레딧을 받아야 협업이 더 쉬워짐
- 최종 론치하는 엔지니어들과 소통하는 것이 중요
- 모델 개발 초기부터 개발/론치 과정을 구체화 하고 소통해야함
- 모델 개발 시 모델을 어떻게 검증할 것인지?
- 모델을 어떤 형태로 엔지니어들에게 넘길 것인지?
- 피처 계산을 어떻게 하느지? 모델 자체는 어떤 포맷인지?
- 모델을 프로덕션에서 A/B 테스트 할 것인지?
- 한다면 최종 성공 판단 지표는 무엇인지?
모델 개발 시 꼭 기억해야 할 포인트 2
개발된 모델이 바로 프로덕션에 론치 가능한 프로세스/프레임워크가 필요
> 예시로, R로 개발된 모델은 바로 프로덕션 론치가 불가능
머신러닝 전반에 걸친 개발/배포 프레임워크가 등장함
> AWS의 SageMaker가 대표적임
>> 검증된 모델을 버튼 클릭 하나로 API 형태로 론치 가능
>> AutoPilot이란 AutoML 기능도 제공
Google Cloud와 Azure 등 다양한 기업에서도 비슷한 프레임워크 지원
- 모델 개발 시 꼭 기억해야 할 포인트 3
- 모델 론치는 시작일 뿐
- 운영을 통해 점진적 개선을 이뤄야 함
- 데이터 과학자의 경우 모델을 개발하고 끝이 아님
- 피드백 루프가 필요함
- 운영에서 생기는 데이터를 가지고 개선점을 찾아야 함
- 주기적으로 모델을 재빌딩하고 배포해야 함
- 이로 인해 탄생한 직군이 MLOps
3-5. MLOps란?
머신러닝 모델의 빌딩/테스트/배포/모니터링 전체 사이클을 담당하고 프로세스를 최대한 자동화 하는 직군이다.
MLOps가 필요한 이유? -> ML 모델은 사용 후 시간이 지나면 성능이 떨어짐
- Data Drift로 인한 모델 성능 저하
- ML 모델에서 가장 중요한 것은 학습 데이터
- 시간이 지나며 훈련에 사용한 데이터와 실제 환경의 데이터가 다르게 변화함
- 이를 Data Drift라고 부르며 이를 모니터링 하는 것이 중요
- 즉 주기적으로 ML 모델을 다시 빌딩해주는 일이 필요함
- 시간이 지나면서 데이터의 성격이 바뀌는데 이를 Data Drift라고 함
- 학습에 사용되는 feature가 바뀌기 때문에 일어난 일
- 시간이 지나며 성능이 저하되고, 주기적으로 리빌딩하고 배포하는 것이 중요함
- 자주 할 수록 자동화 하는 것이 중요하고 그걸 하는게 MLOps 직군임
MLOps vs. DevOps
DevOps가 하는 일?
- Deliver software faster and more reliably in automated fashion
- 개발자가 만든 코드를 시스템에 반영하는 프로세스(CI/CD)
- CI: 개발자가 코드를 작성할 때마다 코드를 실행해 코드에 문제가 없는지 확인하는 것
- CD : CI가 문제 없이 끝난 코드를 자동으로 프로덕션에 배포하는 것
- 시스템이 제대로 동작하는지 모니터링하고 이슈 감지 시 escalation 프로세스 수행
- 작업 대상 : 다른 개발자들이 만든 코드
- On-call 프로세스를 해야
MLOps가 하는 일?
- Deliver ML models fater and more reliably in automated fashion
- 모델을 계속적으로 빌딩하고 배포하고 성능을 모니터링 해야 함
- ML 모델 빌딩과 프로덕션 배포를 자동화하기 위해 계속적인 모델 빌딩(CT)과 배포를 함
- 작업 대상 : 데이터 과학자들이 만든 머신러닝 모델
- 모델 서빙 환경과 모델의 성능 저하를 모니터링하고 필요 시 escalation 프로세스 진행
- Latency : 모델이 얼마나 빨리 결과를 내는지에 대한 시간을 모니터링
- Data Drift 측정 : 어떤 분포대로 feature가 측정되는지 모니터링
- CT : 주기적으로 학습 데이터 수집하여 모델 빌딩, 테스트, 배포, 모니터링 하는 것을 자동화하여 효율성을 높임
CI & CD
CI(Continuous Integration)
개발자들이 코드를 바꾸는 순간 자동으로 모든 테스트가 실행되고 문제없이 끝나면 코드를 패키지에서 배포하기 쉽게 만드는 것
CD(Continuous Delivery or Deployment)
잘 빌딩된 CI가 있는 경우, 결과로 나온 패키지를 프로덕션 서버에 배포하는 것
MLOps 엔지니어가 알아야 하는 기술
데이터 엔지니어가 알아야 하는 기술
- 파이썬/스칼라/자바
- 데이터 파이프라인과 데이터 웨어하우스
DevOps 엔지니어가 알아야 하는 기술
- CI/CD, 서비스 모니터링
- K8S, 도커 등 컨테이너 기술
- AWS, GCP, Azure 등 클라우드 기술
- Infrasturcture as Code(Configuration As Code)
머신러닝 관련 경험/지식
- 머신러닝 모델 빌딩과 배포
- SageMaker, Kubeflow, MLflow 등 ML 모델 빌딩 프레임워크 경험
3-6. 머신러닝 사용 시 고려할 점
학습 데이터의 품질/편향성 여부가 있는지가 매우 중요함
데이터 윤리와 주의할 점, MLOps
데이터로부터 패턴을 찾아 학습하기 때문에 데이터의 품질과 크기가 중요함
데이터로 인한 편향 발생 가능
>> AI 윤리
내부 동작 설명 가능 여부도 중요
>> ML Explainability(머신러닝 모델이 왜 그런 예측을 했는지 이유를 설명할 수 있어야 함)
데이터 권리도 중요한 문제
ChatGPT 같은 모델을 학습 시키며 데이터에 대해 윤리적인, 권리적인 문제가 있음
데이터 기반 AI는 완벽한가? 1
학습 데이터셋의 품질은 어떤가?
> 데이터의 양도 중요하지만 품질도 중요하다
> 미국 EMR(Electric Medical Record)이 아주 좋은 예 : 환자가 어느 병이 있었고 언제 왔고 등을 시스템에 적은 것
>> 시스템의 용도가 환자의 의료 정보를 기록하는 것이 아니라 법적인 제재를 받지 않기 위해 한 것일 수 있음
AI 도입 시 가능한 문제들을 어떻게 해결할 것인가?
> 왜 어떤 결과가 나왔는지 설명이 가능한가?
> 알고리즘 자체에 인종이나 특정 편향성이 있지는 않은가?
많은 시도와 실패가 필요 -> 혁신을 만들어 낼 생태계와 법률이 필요
데이터 기반 AI는 완벽한가? 2
EU의 관련 법규는 많은 시사점을 줌 : Trustworthy AI
> 감독(human agency and oversight) : 누군가 감독을 해야 함. 없이 한다면 무슨 일이 생길지 모름
> 견고성과 안전성(ronustness and safety) : 모델로 인해 생길 수 있는 위험성이 있기 때문에 모델의 견고성과 안전성을 체크해야함
> 개인 정보 보호 및 데이터 거버넌스(privacy and data governance) : 개인정보 보호가 되지 않을 경우를 대비해 법규가 필요함
> 투명성(Transparency) : 모델이 어떻게 동작하는지 보이면 좋음
> 다양성과 비차별성과 공정성(Diversity, nondiscrimination and fairness) : 데이터 수집에 있어서도
> 사회/환경 친화적(Societal and envronmental well-being) : 지구온난화의 주범이 되지 않기 위해
> 문제 발생 시 책임 소재(Accountability) : 모델로 인해 문제가 생겼을 때 책임질 사람이 필요함
잘못된 개인정보 보존으로 인한 패널티
개인정보 잘못 사용할 경우 패널티가 있음
HIPAA(Health Insurance Portability and Accountability Act) - 미국
> 개인 식별할 수 있는 18개의 정보, 의료 시스템과 관련한 EHR, EMR 시스템에 등록되며 부여받은 MRN도 보호를 받음
CDPR/CCPA - 유럽
EU와 미국 캘리포니아 주의 온라인 상에서 개인정보 보호에 관한 법률
데이터 암호화
> 불필요하게 개인정보를 저장하면 안되고, 해야 할 경우 암호화를 해야한다.
집단 이기주의 : 의료분야 예
한국에서 비디오 진료가 안되는 이유?
코로나로 한시 허용된 원격 의료, 의사 반발에 또 표류 : 의료법이 여전히 개정되지 못함
1999년에 이미 서울대 병원과 분당 KT가 원격 진료 연결 시범 사업을 했음
AI 발전에 영향받는 분야의 교육 방향에 대한 시사점
> AI 시대에 따른 의사의 역할
> 기존 교육 시스템 점검 뿐 아니라 재교육 필요성 증대
AI의 발전과 미래 직업의 변화 : 예) 의사의 역할
AI는 의사를 대체하기 보다는 의사의 효율성과 진단/치료의 정확성을 높이는 보조적 역할
> 현재 의사는 다른 잡무로 인해 환자와 충분한 시간을 보내지 못함
> 아무리 경험이 많은 의사라 해도 실수를 할 수 있고 의사마다 굉장디 다른 진료 결과를 냄
>> AI는 진단 절차를 체계적으로 만들고 작업을 빠르고 정확하게 하는데 사용 가능
>>> 일종의 Decision Tree
중단기적으로 의사의 역할에 대해 재고가 필요
> 그에 따라 교육 시스템도 변경이 필요
> 데이터 관련 교육(Data Literacy)이 절대적으로 필요
> 환자와의 대화에 더 많은 시간 쏟기
>> Compassionomics라는 책에 따르면 공감을 잘하는 의사에게 진료를 받은 환자가 더 좋은 결과가 나왔고 번아웃이 덜 되었다고 함
미래의 의사 모습?
현대 비행기의 기장 역할이 좋은 예
> 현대 비행기 조종사는 비행 소프트웨어가 보여주는 각종 정보를 대시보드를 통해 제공받음
> 조종사들은 SW가 주는 정보를 따라하는데 거부감이 없음
> 조종사들은 매 비행마다 안전 보장 위해 반드시 체크해야 하는 리스트가 존재
미래의 의사도 AI 기반의 진단과 치료 정보를 제공 받고 그것을 기반으로 의료 서비스 제공
>> 이를 통해 효율적으로 오진이 적은 의료 서비스 제공
진료 전 체크리스트
>> 병원에서 발생하는 이차감염은 의사/간호사들의 비위생적 행동으로 인해 발생
>>>> ex) 수술 전 손을 씻지 않음
>> 간단하지만 필수적인 행동을 체크리스트로 관리하고 실행
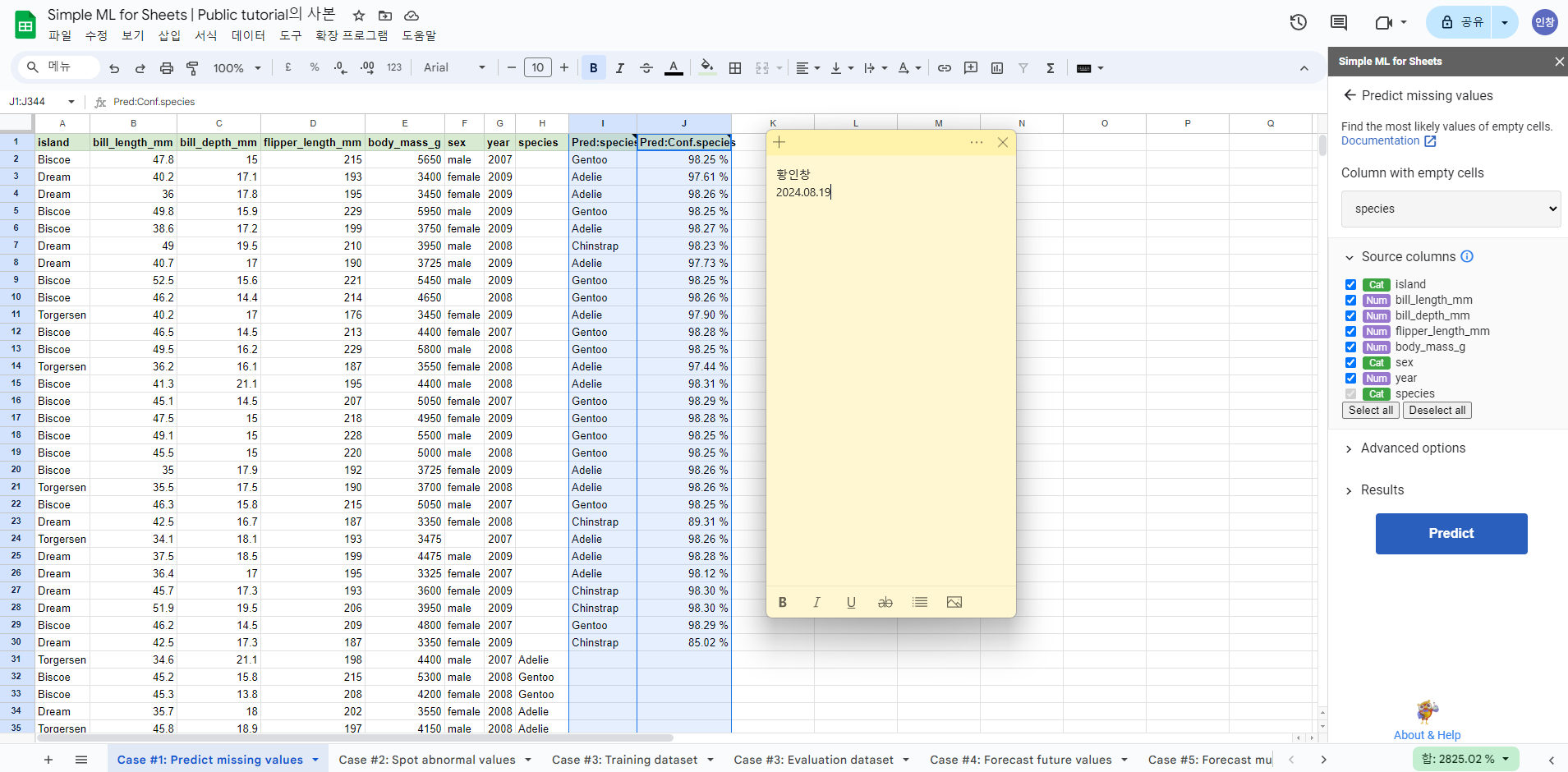
3-7. [실습] 정의하고 차트 만들어보기
구글 스프레드시트로 머신러닝 모델 만들어보기
Simple ML for Sheets : 구글 스프레드시트의 무료 확장판
시트 상의 데이터를 학습 데이터로 간단한 모델을 만들 수 있음
마지막 필드가 예측을 해야 하는 target 필드
https://simplemlforsheets.com/tutorial.html
Predict missing values (Tutorial) — SimpleML for Sheets documentation
Predict missing values (Tutorial) Note This is the Predict missing values tutorial. The Predict missing values documentation is available here. With Simple ML for Sheets, also referred to as Simple ML, everyone can use Machine Learning (ML) in Google Sheet
simplemlforsheets.com
확장 프로그램 > Simple ML for Sheets 클릭, Start
missing values, predict
[실습] 데이터 기반 제품 개선 퀴즈
객관식 1
데이터 분석가가 속한 팀을 뭐라고 부르는가?
①Decision Science
②Product Science > 데이터 과학자 팀
③Data Engineering > 데이터 엔지니어 팀 Data Infra, Platform 등 다양한 이름이 있음
객관식 2
데이터 분석가가 가치를 만들어내는 일반적인 방법이 아닌 것은?
①중요 지표 정의 > KPI 정의라고도 함
②대시보드 작성 및 운영
③데이터 기반 리포트 작성
④ETL 시스템 운영 >> 데이터 엔지니어의 업무
객관식 3
데이터 분석가에 필요한 역량이 아닌 것은?
①SQL > 데이터 관련된 모든 사람이 해야 함
②ELT와 데이터 모델링 > ETL로 데이터 엔지니어들이 가져온 데이터들을 데이터 분석하기 쉬운 형태로 변환하는 것
③통계적 지식
④이벤트 로그 수집 > 데이터 엔지니어나 백엔드 엔지니어가 함
객관식 4
애자일 개발방법론에서 필요한 미팅이 아닌 것은?
①스태프 미팅 > 애자일과 상관없이 팀 내의 시니어 급들이 모여서 팀의 지표를 모여서 하는 것
②플래닝 미팅 > 스프린트 시작 시 어떤 업무를 할 것인지 말하는 미팅
③스탠드업 미팅 > 매일 팀이 다 모여서 어제 뭐 했고 오늘 뭐 할거고 이슈가 뭔지 논의
④회고 미팅 >스프린트 끝날 때 지난 스프린트 돌이켜 보는 미팅
객관식 5
다음 중 일반적으로 KPI라고 할 수 없는 것은?
①매출
②유료고객수
③등록회원수
객관식 6
KPI의 특징이 아닌 것은?
①후행지표
②선행지표
③회사에 중요한 가치를 표현
객관식 7
다음 중 연속적인 값을 예측하는데 사용되는 ML은?
①Binary Classification
②Multiclass Classification
③Regression
④Reinforcement Learning
객관식 8
훈련 데이터에 답이 존재하는 형태의 머신러닝을 무엇이라고 부르나?
①Supervised Learning
②Unsupervised Learning
③Reinforcement Learning
[문제] 데이터 분석 소개 문제
객관식 1
데이터 과학자가 데이터를 분석할 때 가장 먼저 수행해야 할 작업은 무엇입니까?
①데이터 시각화
②모델 검증
③데이터 탐색 및 정제
④예측 모델 구축
객관식 2
다음 중 머신 러닝의 정의로 가장 적절한 것은 무엇입니까?
①데이터를 저장하고 검색하는 기술
②데이터에서 패턴을 학습하고 예측하는 알고리즘
③네트워크를 통해 데이터를 전송하는 방법
④웹 페이지를 디자인하는 기술
객관식 3
다음 중 머신 러닝 모델의 유형이 아닌 것은 무엇입니까?
①압축 모델
②회귀 모델
③강화 모델
④분류 모델
객관식 4
머신 러닝 모델 개발 시 가장 먼저 고려해야 할 사항은 무엇입니까?
①모델의 복잡성
②사용 가능한 데이터의 품질과 양
③하드웨어 성능
④모델 평가 방법
객관식 5
MLOps의 주요 목적은 무엇입니까?
①머신 러닝 모델을 개발하는 데 필요한 하드웨어를 구축하는 것
②데이터 전처리 과정을 간소화하는 것
③머신 러닝 모델의 개발, 배포, 운영을 통합하고 자동화하는 것
④머신 러닝 모델의 정확성을 평가하는 것
객관식 6
머신 러닝 모델의 배포 시 고려해야 할 중요한 사항은 무엇입니까?
①모델의 학습 속도
②데이터의 정규화 방법
③모델의 하이퍼파라미터 튜닝
④모델의 추론 속도와 정확도
주관식 1
ML 모델의 빌딩, 테스트, 배포, 모니터링을 담당하는 직군을 무엇이라고 부르나?
MLOps
기존의 개발팀이 만든 코드에 동일한 일을 하는 직군은 DevOps
주관식 2
ML 모델을 만들 때 사용했던 피쳐의 분포가 바뀌는 현상을 뭐라고 부르나?
Data Drift
이것 때문에 ML 모델을 주기적으로 refresh 해야함
4-2. Gen AI란?_첫 번째
인공지능, 머신러닝, 딥러닝
인공지능 : 인간이 하는 일을 대신 해주는 시스템을 컴퓨터 과학
머신러닝은 인공지능의 일부
딥러닝은 머신러닝의 일부 - 이미지, 비디오, 오디오 등 복잡한 데이터 처리에 강점
Gen AI란?
학습된 컨텐츠를 바탕으로 새로운 컨텐츠를 만드는 딥러닝 기술
- 입력 컨텐츠의 내용을 학습한 모델이 만들어짐 - 예) ChatGPT
프롬프트를 바탕으로 대답을 예측하거나 새로운 컨텐츠를 생성
딥러닝과 Gen AI, LLM의 관계
Generative AI는 딥러닝의 일부
LLM(Large Language Model)은 Gen AI의 일부
딥러닝은 인공신경망을 사용해서 기존 머신러닝 알고리즘이 처리하지 못하는 복잡한 패턴을 처리 가능
딥러닝의 모델 타입
Discriminative
- 분류/예측을 하는 것으로 레이블이 존재하는 데이터에 적용
- 피쳐들과 레이블들간의 관계를 학습
- 예) 개와 고양이 분류
Generative
- 훈련된 데이터와 비슷하지만 새로운 데이터를 생성
- 훈련된 데이터의 통계적 특성을 이해
- 비지도 학습에 해당
- 예) 개 이미지 생성
Gen AI 모델과 일반 ML 모델의 동작 방식
일반 ML 모델에서 y는 보통 숫자, 카테고리, 확률임
Gen AI 모델에서 y는 보통 자연어 문장, 이미지, 오디오 등이 됨
y(출력) = f(x)
f = 모델, x = 입력
Gen AI의 파운데이션 모델 1
광범위한 데이터세트에 대해 학습된 대규모 머신러닝 모델의 한 유형
파운데이션 모델 : 광범위한 데이터셋을 바탕으로 학습 시킨 모델 - pre-trained 되었다고 말함
unsupervised learning or self supervised learning으로 학습이 이루어짐. 데이터셋의 특성을 학습하는 게 목표
대용량 데이터로 학습 하기에 엄청난 시간, 돈, 인력이 필요
트랜스포머 아키텍처를 사용함 > Attention is All You Need
하나의 트랜스포머 안에 인코더, 디코더가 있음
트랜스포머의 수가 늘어날 수록 필요 자원이 증가함
Gen AI의 파운데이션 모델 2
특별한 학습 없이 다양한 작업에 적용 가능하기 때문에 파운데이션이라고 부름
GPT3, GPT4, BERT, T5, DALL-E
Gen AI의 파운데이션 모델과 파인 튜닝
파운데이션 모델을 파인튜닝(Fine-Tuning) 형태로 특정 지식을 학습 시킴
GPT -> ChatGPT
Gen AI 모델들
Generative Language Models
- 훈련 데이터로 제공된 문장들로부터 언어 패턴을 학습한 모델
- 문장의 일부를 입력으로 받으면 다음 단어를 예측
Generative Image Models
- Diffusion과 같은 기술을 사용해 새로운 이미지를 만드는 모델
- 프롬프트를 입력으로 받아 이미지 생성
- 이미지를 입력으로 받아 특정 노이즈 추가해 이미지 변환
Gen AI 모델의 헛소리/환각(Hallucinations)
모델이 부정확하거나, 무의미하거나, 완전히 조작된 정보를 생성하는 경우
> 사실 확인이 필요함
> 발생 이유
>> 학습 데이터의 불충분
>> 학습 데이터의 최신성 부족
>> 학습 데이터의 품질 이슈
>> 모델에게 충분한 컨텍스트가 주어지지 않음 -> 프롬프트 디자인이 중요해짐
4-3. Gen AI란?_두 번째
입력에 따른 Gen AI 모델 : Input이 이미지인 경우
이미지가 Gen AI에 입력으로 사용됨 > 해상도를 높이거나 Image Completion처럼 배경에서 지우고 싶은 객체/영역을 지워줌
출력이 텍스트면 이미지에 제목을 붙여줘라(Image Captioning), Visual QA(이미지에 대해 질문/답변), Image Search(이미지에서 객체 찾기)
출력이 비디오면 비디오로 만드는 것
입력에 따른 Gen AI 모델 : Input이 Text인 경우
출력 - 이미지
이미지나 비디오 생성
출력 - 텍스트
번역, 요약, 질답, 문법 체크
출력 - 오디오
TTS, 작곡
출력 - 비디오, 3D 이미지
출력 - Task
코딩 도움, 특정 업무 비서 역할(Virtual Assitant), 특정 도메인의 일을 자동화(Automation)
멀티모달 파운데이션 모델
파운데이션 모델에 여러 업무를 적용할 수 있도록 파인튜닝해서 다양한 목적에 따라 사용할 수 있음
Gen AI 사용 시 유의할 점
- 잘 사용하는 방법
- 블로그/웹사이트를 위한 독창적인 콘텐츠 생성
- 예술 작품을 위한 영감 창출
- 빠른 프로토타입 및 목업 만들기
- 파일 변환 및 이미지 업스케일링과 같은 단순 작업 수행
- 코딩, 마케팅 등 업무 어시스턴트로 사용
- 잘못 사용하는 방법
- 시험이나 숙제 부정행위를 위해 AI 사용하기
- AI가 말하는 모든 것을 액면 그대로 받아들이기 - 항상 사실 확인 필요
- AI를 사용하여 다른 아티스트의 작품 표절하기 - 저작권 침해 문제
Gen AI의 기타 문제점 1
- Microsoft, GitHub, OpenAI
- 라이선스 코드를 무단으로 재사용한 혐의로 코드 생성 AI인 Copilot에 대한 집단 소송 직면
- 너무 빠른 변화로 인한 법규가 따라가지 못하고 있음
- AI 아트 툴 소송
- Midjourney는 웹 스크랩한 이미지로 모델을 학습시켜 아티스트의 권리를 침해한 혐의로 소송 중
- Getty Image vs. Stability AI
- Getty Image는 Stability AI가 자사 이미지를 무단 사용해 모델을 훈련했다는 이유로 소송 제기
Gen AI의 기타 문제점 2
- 나라에 따른 입장
상대적으로 선진국들은 규제를 더 하려고 함
영국은 미국의 입장과 달리 텍스트 및 데이터 마이닝을 위한 콘텐츠 사용을 보다 허용하는데 적극적
- 사칭을 통한 사기와 가짜 뉴스 생성
- 노동 시장에 주는 잠재적인 악영향
> 많은 수의 스타트업들이 도산
> Stackoverflow 같은 경우 트래픽 감소로 28% 인력 해고
4-4. ChatGPT 발전 살펴보기
GPT(Generative Pre-trained Transformer)
- OpenAI에서 만든 초거대 언어 모델
- 훈련과 예측에 전용 HW를 사용
- LLM
- 처음에는 두 가지 모델을 제공
- Word Completion
- 한국어를 포함한 다양한 언어 지원
- Code Completion
- 참고로 네이버의 초거대 언어 모델은 Word completion만 지원
GPT 3 vs. GPT 4
GPT-3
- 175B 파라미터(175조) = 800GB
- 훈련 비용 4.6M$
- Context Window의 크기는 2048 + 1
- 12,288개의 워드 벡터 사용
GPT-4
- 1T 파라미터(4배)
- Context Window의 크기는 8192 + 1(6배)
- 32,768개의 워드벡터 사용(3배)
- Multi-model(이미지 인식)
GPT-4 Turbo
- Context Window가 128K로 확장됨(300 페이지에 해당)
- 모델의 정확도가 개선됨
- API 기능 개선
- JSON 모드와 시드 제어, 다수 함수 동시 호출
- RAG 기능 제공
- 외부 문서나 데이터베이스를 가져올 수 있음
- 정보 업데이트
- 2021년 9월 컷오프에서 2023년 4월로 갱신됨
경량 언어 모델들
- 메타의 llama(v2까지 나옴)
- 스탠포드의 Alpaca
- llama의 파인튜닝 버전
- 데이터 브릭스의 Dolly
- ChatGPT 같은 대화 모델
학습과 추론이 대형 모델들에 비해 빠름
ChatGPT 소개
- 2022년 11월 30일 발표
- GPT를 챗봇의 형태로 파인튜닝
- RLHF(Reinforcement Learning from Human Feedback) : 사람들이 만들어준 대화 예제로 학습 됐고, 만들어진 모델로 대화 시 ChatGPT 응답을 다시 피드백하고 재학습
- GPT의 지식을 챗봇 형태로 활용 가능
- Prompts 엔지니어링 탄생
- 용도
- 질문에 대한 답변
- 정보 추출
- 번역
- 대화 생성
- 글쓰기 지원
- 코드 생성 및 리뷰
파인튜닝(Fine Tuning)
- 이미 만들어진 모델(Pre-trained Model) 위에 새로운 레이어를 얹히고 다른 용도의 데이터로 훈련하는 것
- GPT는 이를 API로 지원함
- 기본 언어 모델 위에 나만의 모델 생성(버티컬 전용 모델)
ChatGPT 훈련
- RLHF : Reinforcement Learning from Human Feedback
- 사람들이 학습 데이터 생성, 사람 피드백 기반으로 대화하는 인공지능 모델 학습(GPT 모델을 파인튜닝)
- 강화학습 기법 활용해 ChatGPT 학습
ChatGPT 관련 기타
RLHF 훈련을 위한 오픈소스 탄생
MS의 DeepSpeed
데이터브릭스의 Dolly는 대화 학습 세트까지 공개
InsturctGPT
AutoGPT : GPT의 다양한 기능을 활용해 업무 자동화를 해주는 툴
좋은 프롬프트란?
챗지피티에게 역할 부여
- 무슨 일을 해야할지 이야기 하기
- 구체적으로 원하는 형태(텍스트, pdf 등)로 써달라고 하기
- 만약 소개글을 써달라고 한다면, 소개글이 무엇인지 예시로 설명해주기
- GPT가 무엇인지 설명하는 소개글
- 대상 : 챗gpt에 대해 전혀 알지 못하는 사람들
- 톤 : 챗gpt에 대해 중립적으로 쓰되 열정이 느껴지게 써달라
- 제한을 주는 것이 좋음. 이렇게 해달라, 이건 하지 마라 : 8줄 넘지 않게 써줘
- step by step으로 쓰면 좋음. 챗지피티가 뭔지 쓰고 다음걸 써줘라
- 칭찬을 해주면 더 잘함.
ChatGPT 4의 주요 특징
새로운 AI 모델 사용
8배 더 큰 단어 컨텍스트 지원
최신 정보를 얻기 위한 인터넷 서핑 지원
플러그인 지원
언어지원 개선, 답변 더 좋아짐
코딩 부분 기능 개선
코드 인터프리터 지원, 데이터 분석 가능
멀티모달 지원 - 이미지, 텍스트, 오디오
ChatGPT 4.0 플러그인
여행 계획 짤 때 비행기, 숙소, 렌터카 작업 필요함
플러그인 사용하면 링크 걸고 어디서 하라고 알려줌
GPT 4 Turbo
멀티모달 기능 API에 추가
ChatGPT 안에서 이미지 생성 가능
이미지를 API 입력으로 지원
STT Whisper v3 오픈소스로 릴리즈
GPTs : 커스텀 챗봇을 쉽게 만들어주는 기능
특정 목적에 맞는 ChatGPT의 맞춤형 버전
GPT Builter 기능이 제공됨 -> No Code 솔루션(채팅으로 빌딩)
Insturctions, Expanded Knoweldge, Actions로 구성됨
플러그인 기능을 Actions로 발전시킴
4-5. Gen AI 적용 케이스
Case Study : Quizlet
Open AI의 ChatGPT로 구축된 Q-Chat 이라는 AI 개인 튜터
다양한 토픽에 대해 일대일 채팅을 통한 학습 가능
Case Study : Duolingo
- 듀오링고는 GPT-4로 두 가지 새 기능을 구현(프리미엄 기능)
- Roleplay : AI 대화 파트너
- Explain my Answer : 실수 시 문법 규칙을 세분화하여 설명
Case Study : Morgan Stanley
- 자산 관리와 관련한 방대한 내부 데이터 검색용 챗봇 개발을 위해 GPT-4 도입
- 내부 직원용 챗봇으로 PDF 등의 다양한 포맷으로 구성된 데이터 검색 수행
Case Study : Viable
- Viable은 GPT-4를 사용하여 CS 티켓과 같은 자연어 데이터 분석 수행
- OpenAI의 LLM을 파인튜닝하여 비정형 데이터 분석용 모델 생성
- Viable은 이 AI 모델 개발을 위해 거의 3년 동안 OpenAI와 긴밀히 협력
Case Study : Buzzfeed
- 버즈피드와 ChatGPT와 협업
- 퀴즈생성 : 즉석에서 퀴즈 컨텐츠 생성을 위해 ChatGPT 사용
- 레시피 추천 : 음식 브랜드인 Tasty의 레시피를 추천해주는 챗봇 개발에 ChatGPT 사용
4-6. [실습] Gen AI를 활용한 업무자동화
GPT "데이터분석 방법" 에 있음
5-1. 데이터 관련 주의해야할 이슈들
데이터 관련한 최근 변화
- 데이터 소스와 양의 폭발적 증가
- Data Warehouse -> Data Lake
- 모든 조직에서 데이터 생성과 사용 증가
- Data Decentralization
- 데이터 사용자의 폭발적 증가
- Data Democratization : 데이터를 필요한 사람이 접근하게 해주는 것
- SQL/Dashboard skill
- 클라우드 기본 사용
- 개인정보 보호법의 강화
데이터의 증가, 개인정보 보호법의 강화로 인해 새로운 형태의 데이터 관리를 필요로 함
다양한 데이터 관련 이슈들이 발생함
- 무분별한 개인 정보 전파
- GDPR 준수에 엄청난 비용과 시간이 들어감
- 한 번 테이블에 노출되면 불필요한 악순환 발생
- 테이블에 있으니 쓰이고, 그 테이블 기반으로 생성된 다른 테이블로 전파
- 해법 예
- 개인 정보 정의(PII)와 개인 정보를 생성 시점부터 태깅, 불필요시 읽지 않음
- 개인 정보 접근 권한 제어와 로깅 -> 감사 기능
- 특정 개인 정보 추출과 삭제 자동화
- 같은 데이터, 다른 해석
- 지표들의 정확한 정의가 담겨 있는 사전 형태의 정의가 필요 -> 데이터 사전 혹은 데이터 용어집
- 매출(Revenue), 활성 사용자(Active User)
- 데이터 소스, 필터링 등의 조건이 명확해야함 -> 데이터 기반 계산 공식
- 같은 데이터를 기반으로 사용해야함
- 각 지표 계산에서 바탕이 되는 데이터는 무엇인가? Source of Truth
- Being consistent is more important than being correct
- 지표들의 정확한 정의가 담겨 있는 사전 형태의 정의가 필요 -> 데이터 사전 혹은 데이터 용어집
- 너무 많은 대시보드와 비슷한 테이블들
- Data Democratization은 정보 과잉으로 이어지기 쉬움
- Data Discovery 이슈
- Data 관련 요청의 과반수 이상 차지
- Data Infra 비용 증가
- 빅데이터 스케일에서 비슷한 정보의 반복처리 엄청난 비용 증가를 가져옴
- 해법 예
- Data Catalog의 도입
- 자동화 솔루션을 통해 메타 데이터부터 관리
- 데이터셋 오너 지정
- 주기적인 데이터/대시보드 청소작업
- Data Catalog의 도입
- 불분명한 데이터 오너십
- 데이터 양의 증가는 보통 데이터 품질 이슈로 이어짐
- 데이터 품질 이슈는 데이터셋의 불분명한 오너십과 밀접 관련
- 누가 특정 데이터셋의 오너인가?
- 내부 데이터(ETL)
- 외부 데이터(ETL)
- 내부/외부 데이터를 바탕으로 만들어진 데이터(ELT)
- What data do we have?
- 메타데이터부터 관리 시작
- 데이터 양의 증가는 보통 데이터 품질 이슈로 이어짐
- 메타 데이터의 부족
- Source of Truth가 무엇인가?
- 특정 데이터셋의 경우
- 누가 주인인가?
- 어떻게 생성된 데이터인지 알 수 없음
- Upstream 데이터를 변경하는 경우 확신이 없음
- downstream. 어디가 고장날지 알 수 없음
- 해법 예
- 중요 데이터별로 오너 지정
- 데이터 별로 다양한 태그 혹은 분류체계 적용(예: PII)
- 데이터 리니지 자동 파악
- 조직이 커지며 Data Silo 발생
- 앞서 이슈가 증폭됨
- 비슷한 일을 여러 팀에서 반복
- 동일 데이터를 여러 조직에서 중복 수집하고 처리
- 데이터 독점이 권력이 되기도 함
- 해법 예
- 조직 전반에 걸친 메타 데이터 관리/유지
- Data Mesh가 하나의 해법이 될 수 있음
- Monolithic Data Lake to Distributed Data Mesh
- 하지만 아직은 초기 단계의 기술